Introduction to Cloud-Native Geospatial
Guillaume Sueur
A New Era of GIS
Since its inception, Geographic Information Systems (GIS) have relied on a simple but often cumbersome model: if you wanted to work with spatial data, you had to download the entire dataset. Whether it was a satellite image, a high-resolution elevation model, or a nationwide vector dataset of roads, the expectation was that you would first get a full copy of the file and only then start working with it. This meant huge storage requirements on the user side (yes, we all remember the GIS guy’s laptop requirements…), as well as challenges in data dissemination and endless downloads and uploads. Then came OGC services like WMS, WCS, and WFS, presumably allowing users to access online geodata services from their desktop applications without having to download them first. But this came at a cost. Not only were these services not always reliable, but they were often complex and required perfect and complete client-side integration to provide all the promised functionalities to the user. As is often the case, most implementations covered the first 80% of functionality but left the crucial last 20% behind, leaving the user high and dry—forced to code a dedicated client for their specialized task on their specific dataset. Cloud-Native Geospatial is a shift away from this paradigm. Instead of downloading files in their entirety or accessing them through a service, cloud-native tools are designed to be serverless and access only the portions of data that are needed at a given moment. This is possible thanks to a fundamental underlying technology that is part of the widely used Internet HTTP protocol: HTTP range requests.
HTTP Range Requests: The Linchpin of Cloud-Native Geospatial
An HTTP range request is a feature of the Hypertext Transfer Protocol (HTTP) that allows a client (such as GIS software, a web application, or a Python snippet) to request only a specific portion of a file stored on a remote server, rather than downloading the entire file. This mechanism isn’t new and has been extensively used in fields beyond GIS. For example, it enables video streaming platforms to buffer only the next few seconds of a video instead of loading the entire film at once. I’m not saying that porn brought us Cloud-Native Geospatial, but you get the idea. In GIS, range requests enable applications to retrieve only the specific chunk of a Cloud-Optimized GeoTIFF (COG) that corresponds to the area of interest or only the necessary rows from a GeoParquet file containing millions of vector features. This eliminates the need to store enormous files locally while ensuring efficient access to spatial data. OK, I see where you’re going with this… So yes, if your SQL query covers the entire dataset, it will need to be almost completely downloaded—there’s no further magic. But you shouldn’t be doing that, should you?
Formats That Enable Cloud-Native Geospatial
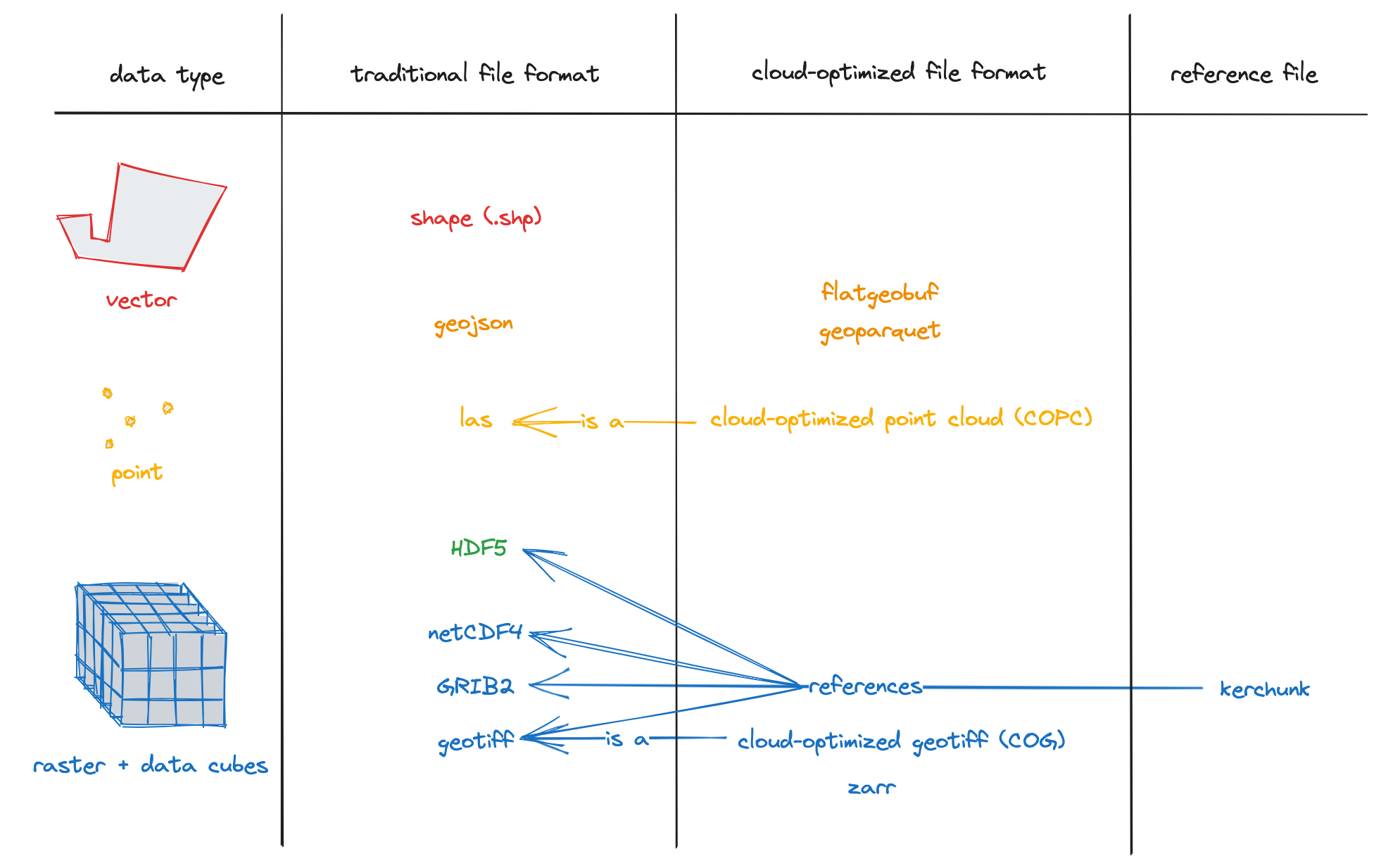 Diagram of some cloud-optimized format provided by the excellent Cloud-Optimized Geospatial Formats Guide
Diagram of some cloud-optimized format provided by the excellent Cloud-Optimized Geospatial Formats Guide
Cloud-Native Raster Formats
Cloud-Optimized GeoTIFF (COG)
COG is a regular GeoTIFF but structured to allow software to retrieve specific sections without downloading the full file. After all, the GeoTIFF format is nothing more than an archive format—a container in which you can store different elements together, such as a BITMAP image and its pyramid of JPEG tiles. So, COG is simply a way to organize that properly, ensuring that everything the client needs to access useful data blocks is readily available: an index at the beginning of the file and a tile-structured content layout with the appropriate resolution and compression.
Zarr (for large, multi-dimensional raster data)
Zarr is designed for cloud-native storage of multidimensional data, such as climate models, environmental simulations, and time-series raster datasets. It’s like an image but with several other dimensions like elevation and time stored in an hyper-cube.
Cloud-Native Vector Formats
GeoParquet
GeoParquet is already gaining traction as a game-changer for spatial data storage, but its evolution is far from over. While it was initially developed as an extension of Apache Parquet to handle geospatial features, the broader Parquet ecosystem is now integrating spatial capabilities directly into its core specification (see Cloud native Geo Blog written by the best Geoparquet experts). This means that in the near future, there may be no need for a separate “GeoParquet” format—spatial data will be a fully native part of Parquet itself. Yes, spatial won’t be special anymore, but you can still be ! This shift has major implications. First, it will strengthen interoperability between geospatial and non-geospatial datasets, making it easier to analyze spatial features alongside tabular data within cloud warehouses like Google BigQuery, AWS Athena, and DuckDB (see below). Second, it paves the way for even deeper adoption of Parquet as the de facto standard for large-scale, distributed data processing. From a practical standpoint, GeoParquet already solves many of the problems that plagued traditional vector formats. The Shapefile, despite its longevity, is an aging format with severe limitations, including file size constraints, lack of support for modern compression techniques, and a rigid schema. GeoJSON, while more flexible, is notoriously inefficient for large datasets due to its text-based structure. By contrast, GeoParquet brings several advantages:
- Columnar Storage → Faster querying especially for large datasets.
- Efficient Compression → Stores data in a highly optimized binary format, drastically reducing file sizes compared to GeoJSON.
- Selective Data Access → Enables applications to retrieve only the necessary rows and columns without scanning the entire dataset.
At this point, anyone still batch-downloading nationwide datasets in Shapefile format should at least consider trying GeoParquet. The ecosystem is moving forward quickly, and with native spatial support coming to Parquet itself, the transition to cloud-native geospatial data workflows will only accelerate.
PMTiles (Tiled Vector Data)
PMTiles are designed primarily for efficient web map display rather than desktop GIS usage, though they can still be accessed in QGIS with the right plugins. What makes PMTiles particularly powerful is its cloud-native access model, which enables applications to retrieve individual tiles via HTTP range requests, eliminating the need to download the entire file. Another key advantage of PMTiles is its ability to store multiple resolutions of a dataset within the same file, similar to how a TIFF pyramid optimizes raster data. This hierarchical structure ensures that when a web mapping application requests tiles at different zoom levels, only the necessary level of detail is loaded—keeping map rendering fast and efficient, even for very large vector datasets. Unlike MBTiles, which typically requires a tile server for online access, PMTiles is designed to work directly from cloud storage, reducing infrastructure complexity. This makes it an excellent choice for serverless web mapping applications, allowing developers to serve high-resolution basemaps and dynamic vector layers without maintaining a traditional tile server setup. You can see pmtiles datasets in action on this interactive Overture Maps Explorer
Cloud Storage: Managing Accessibility and Costs
Since Cloud-Native Geospatial relies on remote data access, the choice of cloud storage provider is crucial. Services like AWS S3, Google Cloud Storage, and Azure Blob Storage are commonly used, but they come with costs for data egress (i.e., the cost of retrieving data from the cloud). This can become expensive, especially for popular and frequently accessed datasets which can quickly make your bill skyrocket…
A compelling alternative is Cloudflare R2, which offers a major advantage: zero egress fees. Unlike AWS S3, where downloading data can become a significant expense, Cloudflare R2 allows GIS professionals and organizations to store geospatial datasets at a lower cost while ensuring that users can access them efficiently. By combining R2 with COG, PMTiles, and GeoParquet, it is possible to create highly scalable and cost-effective geospatial workflows.
One of the main challenges of working with cloud storage is managing access credentials. Many cloud providers require users to authenticate with API keys or access tokens, which can be cumbersome, especially when working with multiple services which don’t all use the same conventions. Some GIS tools provide built-in integrations to simplify this process, but for advanced workflows, users often need to manually configure environment variables or use specialized authentication methods such as AWS IAM roles. These complexities can be a barrier to adoption, making it essential for GIS professionals to develop a solid understanding of cloud security best practices.
Three Hands-On Examples to Bootstrap Cloud-Native GIS Practice
1. Loading a Cloud-Optimized GeoTIFF in QGIS Without Downloading It
Many satellite imagery providers now distribute data as COGs. To load one directly into QGIS:
- Open QGIS and go to Layer → Add Layer → Add Raster Layer.
- Instead of selecting a file, enter the following URL as a remote raster source:
https://sentinel-cogs.s3.us-west-2.amazonaws.com/sentinel-s2-l2a-cogs/36/Q/WD/2020/7/S2A_36QWD_20200701_0_L2A/TCI.tif - Click OK, and the image will be loaded directly from the cloud. You can see the same file directly used by an online map in this OpenLayers example
2. Querying a GeoParquet File with DuckDB
Instead of using a traditional PostGIS database, GeoParquet allows users to perform fast queries on vector data without needing a database server.
REMOTE_FILE=https://data.source.coop/cholmes/eurocrops/unprojected/geoparquet/FR_2018_EC21.parquet
duckdb -c "duckdb -c "INSTALL spatial;LOAD spatial;SELECT EC_trans_n FROM '$REMOTE_FILE' WHERE ST_Intersects(geometry, ST_Point(2.878213043724707,46.536744281396125)) ;"You will get the type of culture located at this precise spot in France :
Long rotation meadow (6 years or more)
But you may notice as well that it took a while for the query to be processed, because in order to perform the ST_Intersects function, DuckDB had to download the whole content of the geometry column, for the whole 9.52 million rows… So remember that for now the geometries are not efficiently indexed in GeoParquet, conversely to the other columns, which allows us to perform the query
duckdb -c "INSTALL spatial;LOAD spatial;SELECT sum(surf_parc) FROM '$REMOTE_FILE' WHERE EC_trans_n='Vine: wine grapes';"and have a result in a few seconds only, even if it implied parsing all the specified rows and adding their surf_pac value.
Conclusion
Cloud-Native Geospatial is transforming how GIS professionals work with spatial data. Instead of relying on distant services or local storage, we now have the ability to store massively and remotely on simple Cloud Storage object platforms and use the data serverless with more desktop tools able to access data by chunks and take advantage of efficient indexing techniques across column-oriented databases formats. Massive datasets are already available online for you to test and discover more about this. Check out the Overture Maps datasets or Foursquare’s OpenSource places. This is definitely Cloud-Native Geospatial in action ! If you are interested in knowing more about Cloud-Native Geospatial and want to meet all the people involved into making it happen, join the CNG Conference in Snowbird, Utah by the end of April for 2.5 days of presentations, demos, panels, hacking, and workshops.